Claude 3.7 is here, and early reactions are pouring in. Is this Anthropic’s biggest AI leap yet—or just another update in a crowded field? Users are already testing its coding abilities, reasoning improvements, and extended thinking mode. Here’s what they’re saying.
To date, the only LLM I’ve paid for has been ChatGPT plus. I am very interested to try the upgraded Claude model now 3.7 is out and test it out for a few months. This article is meant to summarize early reactions, enjoy!
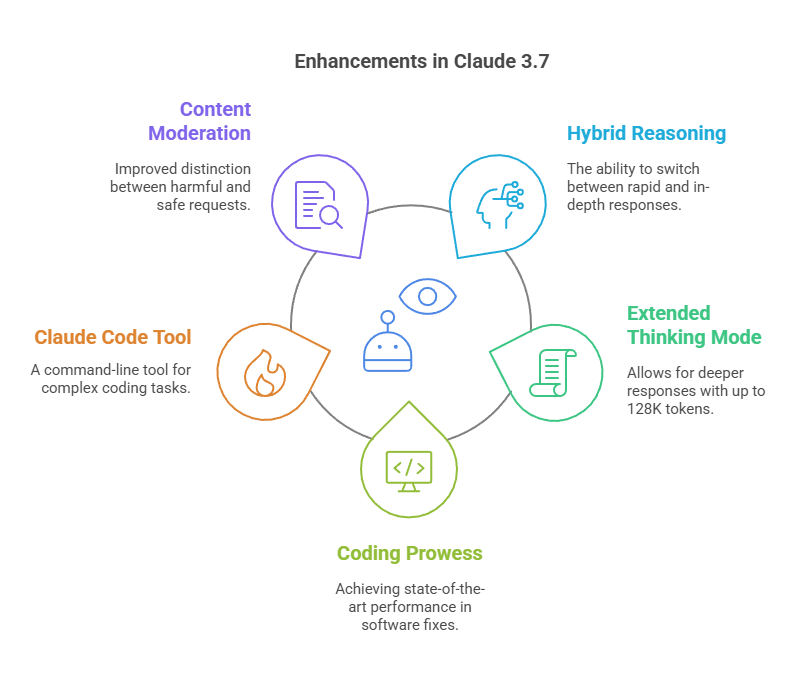
What’s New with Claude 3.7?
Anthropic calls Claude 3.7 its most capable model yet, and early tests suggest major advancements. Key highlights include:
- Hybrid Reasoning: The model can switch between rapid responses and in-depth analytical thinking, making it more adaptable.
- Extended Thinking Mode: Users in the API can allocate more “budget” for deeper responses, up to 128K tokens.
- Coding Prowess: It’s setting new records, achieving state-of-the-art performance on SWE-bench Verified (a benchmark for AI-driven software fixes).
- Claude Code: A new command-line tool for agentic coding, letting developers offload complex engineering tasks directly from the terminal.
- Smarter Content Moderation: Unnecessary refusals have reportedly dropped by 45%, improving the model’s ability to distinguish between harmful and safe requests.
The Verdict from Early Users and Early Reactions
Public reaction is strong and opinionated. Here’s a breakdown of the most common takes so far:
🚀Coding Performance Stuns Developers
The loudest praise is Claude 3.7’s coding capabilities. Developers are blown away by its improvements:
- “It coded this game in one shot—3,200 lines of code.”
- “It’s comedy gold how much better Claude is at code than OpenAI’s models.”
- “I just rewrote a massive PHP codebase I’ve never touched before—Claude did it instantly.”
- “Added 15+ files flawlessly. They actually look good.”
- “Output nearly 2,000 lines of code in one go—previous versions would have stopped after 1/3 of that.”
- “Rust users: It’s no longer fighting the borrow checker endlessly.”
🧠 Smarter, More Nuanced Responses
Non-coding users report a noticeable boost in reasoning, comprehension, and answer quality.
- “I don’t have to reword my prompts as much—it just gets it.”
- “Answers feel more complete. Less ‘generic AI talk.’”
- “Extended thinking mode actually makes a difference in research tasks.”
🤔 But Some Users Aren’t Fully Convinced
While many praise the update, some find the improvements incremental rather than groundbreaking.
- “Claude 3.7? The name downplays the improvements. This should have been Claude 4.”
- “I tested it against GPT-4o, and Claude 3.7 lost badly.”
- “Better than 3.5, sure, but not night-and-day different.”
⚠️ A Few Pain Points Remain
Here are some of the critical opinions from initial reactions
- Daily limits continue to frustrate power users. Even paid subscribers report hitting their cap too soon.
- “Thinking Mode” issues: Android users say the button is disabled, limiting access to extended reasoning.
- Some users expected a bigger leap and feel GPT-4o still holds the edge in general tasks.
- Some users warn
Claude 3.7 vs. The Competition
So how does it stack up against GPT-4o, Gemini, and Grok?
- 🔹 Coding: Claude 3.7 leads. Users say it outperforms GPT-4o, especially for large-scale projects.
- 🔸 General AI Tasks: GPT-4o still has the edge. Many claim it’s smoother across diverse use cases.
- 🔹 Reasoning & Knowledge: Mixed results—Claude 3.7 scores top marks in tool usage and deep reasoning but varies depending on the task.
- 🔸 Speed & Efficiency: GPT-4o is reportedly faster for most non-coding tasks.
Check out our Resources Hub to see some of the other models.
Introducing Claude Code
Anthropic’s new terminal-based tool enables:
- Direct codebase modifications via natural language commands
- Automated test case generation and execution
- Git integration for commit management
- CLI tool orchestration
Early adopters report 45-minute continuous coding sessions where Claude 3.7 Sonnet iteratively improves solutions through test-driven development cycles. Access requires joining the limited research preview through Anthropic’s developer portal
Final Thoughts from Early Reactions
Claude 3.7 delivers major improvements, especially in coding and hybrid reasoning. While developers are ecstatic, general users have more mixed reactions, and some feel the model still trails GPT-4o in everyday tasks. People seem to like the human writing style. The main negative seems to be the usage limits, especially though the native UI (as opposed to through an API or alternative UI).
Regardless, this update signals serious momentum from Anthropic—and raises the stakes for future AI competition. I’m really happy AI competition exists as we’re getting better and better products every few weeks. For an AI based prediction on what else may be coming in the next 6 months be sure to check out my other recent article AI Advancements 2025: What to Expect in the Next Six Months.